
超越DeepSeek GRPO的关键RL算法,字节、清华AIR开源DAPO
超越DeepSeek GRPO的关键RL算法,字节、清华AIR开源DAPODeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。
来自主题: AI技术研报
7123 点击 2025-03-18 17:14
 搜索
搜索
DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。
HuixiangDou 是群聊场景的 LLM 知识助手。

Neurobo(弈智交互)是一家位于上海的创业公司,获得前百度总裁、微软副总裁陆奇博士创办的奇绩创坛的投资。团队核心成员来自清华大学与日本筑波大学等海内外名校,致力于结合 LLM 与现实场景数据,让二次元用户可以将「谷子」变为随身相伴,随时触达的实体情感伴侣。
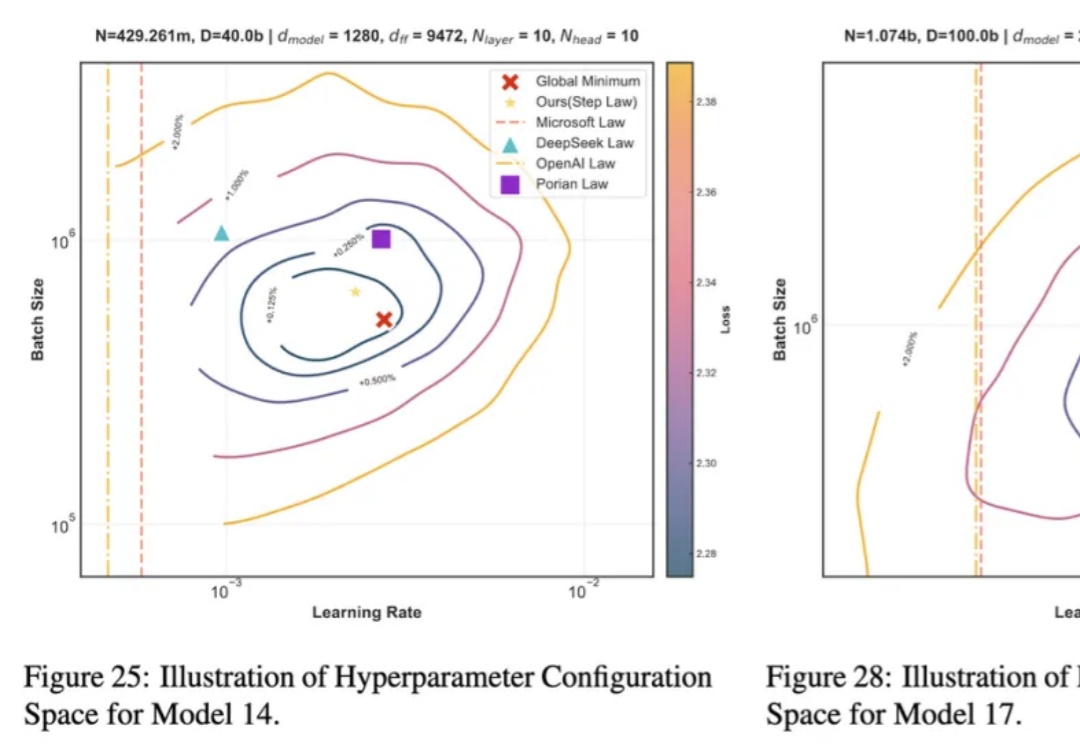
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
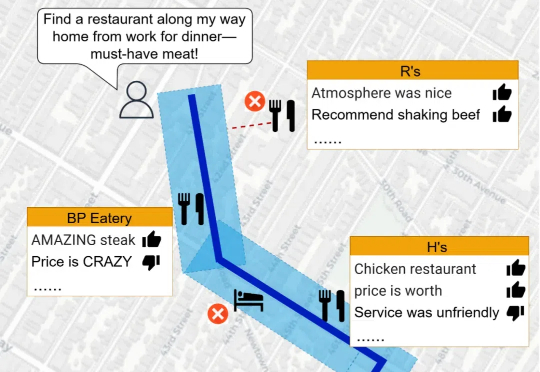
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。

Manus 的产品名,意思为“手”,来自拉丁文 "mens et manus" —— 知行合一。它体现了一种理念:知识和智慧必须通过身体力行才能对世界产生正向影响。这就是 Manus 的追求,为 LLM 做一双能巧妙调用工具的手,从而扩展人的能力,让你心中的愿景成为现实。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。

我们现在使用 LLM 来处理所有的理解工作,并确保我们不会向用户发送任何生成文本,这样我们就可以完全自信地说,我们没有幻觉的风险,没有提示注入和劫持等风险。
最初,查询扩展是为那些靠关键词匹配来判断相关性的搜索系统设计的,比如 tf-idf 或其他稀疏向量方案。这类方法有些天然的缺陷:词语稍微变个形式,像 "ran" 和 "running",或者 "optimise" 和 "optimize",都会影响匹配结果。虽然可以用语言预处理来解决一部分问题,但远远不够。技术术语、同义词和相关词就更难处理了。